
Access Is Not Agency
Teams are giving agents more connectors before they have defined what the agent is allowed to change. That is not agency. That is reach with a larger blast radius.



The agent everyone calls powerful
Imagine the demo.
The agent can read Slack. It can search email. It can query the CRM. It can open GitHub issues, check the billing system, browse docs, edit a spreadsheet, draft a customer reply, and call three internal APIs.
Everyone in the room calls it powerful.
That is the first mistake.
The question is not what the agent can access. The question is what it is allowed to change.
Can it send the email, or only draft it? Can it update the customer’s plan, or only propose the update? Can it refund the invoice, revoke a token, merge the pull request, notify the vendor, reassign the ticket, delete the record, file the report, or trigger the incident workflow?
Once an agent can act through tools, the real system is no longer the model. The real system is the action contract around the model.
Access is reach. Agency is permissioned action under constraints.
This distinction sounds small until the first bad run. A read-only research assistant can waste time. An agent with billing access can create obligations. An agent with email access can speak for the company. An agent with deployment access can turn a wrong inference into infrastructure.
More tools do not automatically make the agent more agentic. More tools expand the surface on which judgment must be engineered.
A tool call is not agency
A confidence score is not evidence. A tool call is not agency.
Tool access tells you what an agent can touch. It does not tell you what the agent is authorised to decide, what must be checked, what becomes binding, or what happens after failure.
That is why the current agent conversation feels slightly wrong. People talk as if the next leap is connectors. Give the model Slack, Gmail, GitHub, Linear, Notion, Salesforce, Stripe, a browser, memory, and MCP servers, then wait for autonomy to emerge.
But a connector is not a decision right.
A connector gives the agent a door. It does not define whether the agent may walk through the door, what it may carry, who must inspect the bag, whether the door locks behind it, or who reviews the camera footage if something goes missing.
A connector is a door. Agency is a contract about who may walk through it.
This is not a metaphorical governance concern. It is the operating surface.
Security lawyers are already asking the practical version of the same question. When an agent can send emails, modify records, execute transactions, or orchestrate other systems, deployment stops looking like ordinary software access and starts looking like delegated operational authority. The useful questions become blunt: what authority does the agent have, can it read only or modify systems, which actions require human approval, how is behaviour audited, and how do you stop it if it becomes a threat? 1
That is the missing layer in most agent demos. They show reach. They do not show authority.
The stack nobody wants to name
If you want to know whether an agent has real agency, do not start with the model card. Start with the rights stack.
What can it see?
What can it change?
What must it prove before the change becomes real?
What triggers escalation?
What permission disappears after a bad run?
That last question matters most because it reveals whether the system has a memory of failure. A human employee loses trust after a bad judgment. They may lose budget authority, approval rights, admin permissions, or the ability to act without supervision. Most agents do not lose anything. They fail, get patched, and return with the same action surface.
That is not delegation. That is amnesia with API keys.
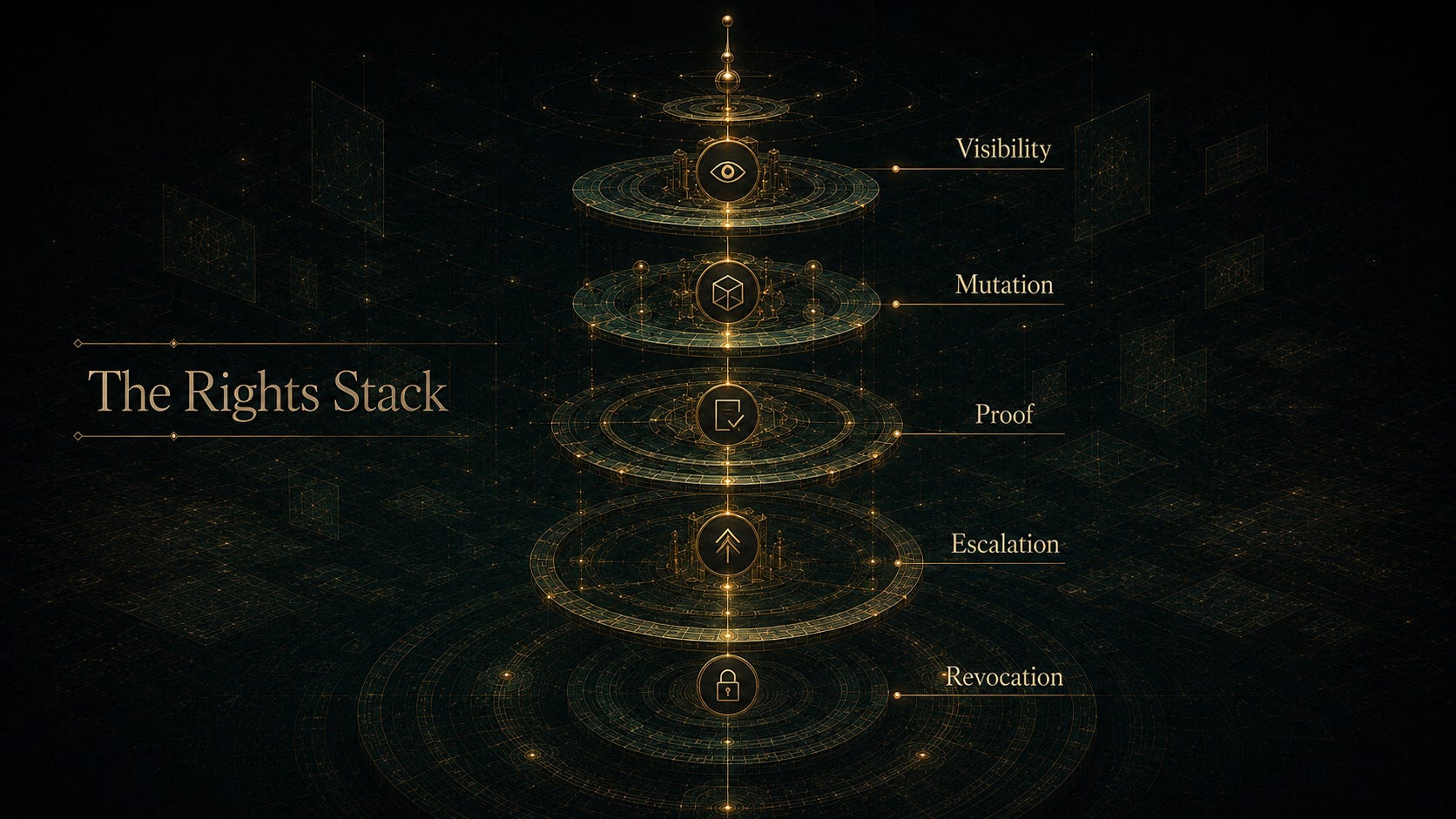
An agent action stack has at least five layers.
The first is visibility: which data, tools, documents, messages, logs, tickets, accounts, and systems the agent can inspect.
The second is mutation: which objects the agent can change. Reading a customer record and changing a customer record are different powers. Drafting a reply and sending a reply are different powers. Proposing a deployment and executing a deployment are different powers.
The third is proof: what the agent must produce before a mutation becomes real. That could be a test run, a diff, a trace, a policy check, a second-model review, a human approval, a simulated dry run, or an evidence bundle.
The fourth is escalation: when the agent must stop and hand the decision to someone else. Not “human in the loop” as a slogan. A named escalation condition. Missing context. High reversibility cost. Conflicting instructions. External communication. Payment movement. Privilege change. Legal exposure.
The fifth is revocation: what changes after the agent fails. If a bad run does not shrink future permissions, the system has no operational immune response.
The hard part is not giving the agent a tool. The hard part is deciding when the tool stops being available.
This is why “least privilege” becomes more important in agent systems, not less. A normal app executes known code paths. An agent chooses a path through a tool surface at runtime. The permission is no longer just “can this service account call this API?” The question becomes “for this task, with this evidence, under these constraints, should this agent be allowed to perform this action now?”
That is a different shape of access control.
The bottleneck moved from capability to authority
You can see the migration in deployed behaviour.
Anthropic’s research on agent autonomy is useful because it does not only ask what models can theoretically do. It looks at real product behaviour. In Claude Code sessions, the long tail of unsupervised turns got longer between late 2025 and early 2026. More interestingly, experienced users both auto-approve more and interrupt more. They do not simply trust the agent blindly. They shift from approving every step to letting longer runs proceed, then intervening when timing, uncertainty, or risk demands it. 2
That is what practical autonomy looks like. Not zero oversight. Selective oversight.
The better the agent gets, the less useful per-step approval becomes. But that does not make approval disappear. It moves approval upward.
The better the agent, the higher the approval rises. Selective oversight beats per-step oversight only when the boundaries are named.
Instead of “may the agent call this tool?” the important question becomes “which category of action is this, under which authority, with which proof, and what happens if the run crosses a boundary?”
This is why a more capable agent can make a weak control stack worse. It will move faster through a larger action surface. It will chain tools. It will recover from errors. It will confidently produce intermediate artefacts that look plausible. It will make the system feel smoother right up to the point where the wrong action becomes real.
The bottleneck has moved. It is no longer only model capability. It is decision-rights routing.
Who gets to decide what?
Under which conditions?
With what evidence?
With what right to commit the change?
With what right to continue after failure?
The organisations that answer those questions will get more agency from smaller tool surfaces than the organisations that connect everything and call it autonomy.
Older institutions already know this
Companies do not give humans “access” and call the job designed.
A junior analyst can see a model. They may not approve a trade.
A support rep can view a customer record. They may not issue a large refund without approval.
An engineer can open a pull request. They may not deploy to production alone.
A finance employee can prepare a payment. They may not release it without a second sign-off.
Corporate delegation is an action-rights system. So are IAM, accounting controls, and clinical protocols. They all separate seeing, recommending, approving, executing, logging, and reviewing.
A control system without revocation is not a control system. It is trust with a longer leash.
Agents are forcing software teams to rediscover that distinction inside product architecture.
The strongest academic frame I found for this comes from a 2026 paper on Autonomous Administrative Intelligence. The paper is conceptual, not empirical, so it should not be treated as proof that the architecture works. But its structure is exactly the one agent teams need to notice: strategic control, agentic decision formation, and governance validation are separate layers. The agent may form an administrative decision. A governance layer validates it against rules and constraints. Execution and recording happen only after that validation. Humans shift from constant supervision toward intent, boundaries, and exceptions. 3
That is the right shape.
Do not ask whether the agent can complete the task.
Ask where decision formation ends and validation begins.
If those are the same place, the agent is not operating under an action contract. It is operating under trust.
Trust is not bad. Trust without revocation is not a control system.
Tool design is contract design
This is where tool protocols start to matter, but not for the reason most people say.
The industry is building standard ways for agents to connect to external systems. The most prominent is MCP, Anthropic’s Model Context Protocol. The lazy version of that story says MCP is important because it gives agents more tools. The better version says it is important because it makes the tool boundary explicit enough to inspect, version, test, authorise, and debug.
That distinction is not just engineering taste. It changes what you can see when things go wrong. Anthropic’s own engineering guidance frames tools as contracts between deterministic systems and nondeterministic agents. Their names, descriptions, return values, and failure modes affect whether an agent can use them reliably. A tool built for a human developer is not automatically a good tool for an agent. 4
Once you accept that, the “more connectors” story becomes incomplete. Tool count is not the win. Contract quality is the win.
Tool count is not the win. Contract quality is the win.
A strong tool contract tells the agent what the tool does, what inputs it needs, what output means, what failure looks like, and what the agent should not infer. A strong action contract goes further. It says when the agent may call the tool, when the call may mutate something, what proof is needed, and where the trace goes.
Early benchmarks are confirming this. When researchers tested agents across hundreds of real tools and multi-step tasks, the failures were not mainly in the final answer. Agents chose the wrong tool, passed wrong parameters, recovered badly from errors, or produced plausible answers from broken execution traces. 5 The system looked like it worked. The trace showed that it did not.
That is the pattern to watch. Tool-using agents need diagnostics at the contract layer, not only at the output layer.
If your agent can touch ten systems and your only observable is “task succeeded,” you are blind in the place where the system is becoming dangerous.
The Agent Action Rights Test
Run this on the most powerful agent or workflow you currently use.
Do not pick a toy. Pick the one you are most tempted to trust. The coding agent with repo access. The sales assistant with CRM access. The ops agent with incident tooling. The analyst agent with warehouse access. The support agent with customer email access.
Then answer five questions without hand-waving.
What can the agent see?
What can the agent change?
What must it prove before the change becomes real?
What triggers escalation to a human?
What permission disappears after a bad run?
Most teams can answer the first question.
Some can answer the second.
Almost no teams can answer all five.
That is the diagnostic.
If you cannot answer “what can it see?”, you do not have an inventory.
If you cannot answer “what can it change?”, you do not have a permission model.
If you cannot answer “what must it prove?”, you do not have verification.
If you cannot answer “what triggers escalation?”, you do not have oversight.
If you cannot answer “what permission disappears?”, you do not have learning at the authority layer.

You may still have a useful agent. You may even have a high-performing one. But you do not yet have trustworthy agency. You have a tool-using system whose action rights are partly implicit.
Implicit action rights always become visible after an incident.
The dangerous middle
There is a tempting objection here.
If we make every action permissioned, verified, escalated, logged, and revocable, will we not kill the point of agents?
Yes, if you do it badly.
The goal is not to turn every agent into a form-filling intern that asks permission before breathing. The goal is to match authority to consequence.
Read-only Slack search should be cheap. Drafting a customer reply should be cheap. Local reversible edits should be cheaper than external irreversible commitments. Sending the customer email, refunding the invoice, revoking the token, merging the pull request, or releasing the payment should pass through stronger gates.
Good action rights are not one wall around the whole system. They are a slope.
Good action rights are a slope, not a wall. Authority should track consequence.
The agent gets wider freedom where mistakes are cheap, visible, and reversible. It gets narrower freedom where mistakes are expensive, silent, and hard to undo.

That is also how good human organisations work. The graduate can model scenarios. The manager can approve a small budget. The director can reallocate headcount. The board can approve the acquisition. Authority changes with consequence.
Agents need the same gradient.
The mistake is treating “human approval” as the only safety primitive. Approval is expensive. It also fails when humans approve too much, too fast, or without the evidence needed to judge. The better primitive is action-rights design: proof requirements, escalation rules, default-deny mutations, bounded autonomy, time-limited permissions, separate approval and execution, traces that survive, and permissions that shrink after failure.
That stack is harder than adding another connector.
That is why it will matter.
What to build next
If you are building or buying agent systems, ask for the action contract before the roadmap.
Ask the vendor to show the permission tiers, not only the integration list.
Ask which actions are read-only, draft-only, approval-gated, automatically executable, or forbidden.
Ask where traces live.
Ask how tool calls are mapped to business authority.
Ask what happens when the agent is tricked, confused, stale, incomplete, or too confident.
Ask how a bad run changes the next run.
This is where the serious agent market will split.
One side will sell reach: more connectors, more memory, more tools, more environments, more background work.
The other side will sell agency: permissioned action, bounded autonomy, proof before commitment, escalation when context breaks, and revocation when trust is lost.
Reach will demo better.
Agency will survive contact with the organisation.
Reach demos well in the room. Agency holds up in the incident review.
Before next week, run the Agent Action Rights Test on one workflow. Not your whole stack. One agent. One workflow. Write the five answers in a note. If the fifth answer is blank, you found the missing layer.
The agent did not need another tool.
It needed a smaller right to be wrong.
If you run the test, which answer was hardest to fill: what it can see, what it can change, what it must prove, when it escalates, or what permission disappears?
If this piece landed
This article builds on the claim that a confidence score is not evidence. If the rights stack resonated, the deeper version is Your AI Agent Stack Is Solving The Wrong Problem, which walks through the full contract stack for agent systems. And if you want the five laws that run underneath all of it, start with The Five Laws of Durable Systems.


Footnotes
Stoel Rives, Securing and Contracting Agentic AI (20 February 2026), https://www.stoel.com/insights/publications/securing-and-contracting-agentic-ai. The page is especially useful because it moves quickly from generic “agentic AI” language to concrete authority, IAM, audit, monitoring, integration, and shutdown questions.
Anthropic, Measuring AI Agent Autonomy in Practice (18 February 2026), https://www.anthropic.com/research/measuring-agent-autonomy. Treat the metrics as first-party vendor telemetry, not independent industry prevalence. The useful point here is the oversight pattern: longer autonomous runs coexist with experienced users interrupting more selectively.
Aravindh Sekar, Autonomous Administrative Intelligence: Governing AI-Mediated Administration in Decentralized Organizations, Administrative Sciences 16(2), 95 (12 February 2026), DOI 10.3390/admsci16020095. The article is theory-building, not empirical validation, but its separation of strategic control, agentic decision formation, validation, execution, recording, and exception governance is the right architectural distinction for this argument.
Anthropic, Writing Effective Tools for AI Agents (2025), https://www.anthropic.com/engineering/writing-tools-for-agents. Anthropic frames tool definitions as contracts between deterministic systems and nondeterministic agents, and emphasises realistic multi-step tool evaluations rather than single-call demos.
Bandi et al., MCP-Atlas: A Large-Scale Benchmark for Tool-Use Competency with Real MCP Servers (arXiv 2602.00933, January 2026), https://arxiv.org/pdf/2602.00933. The benchmark reports 36 MCP servers, 220 tools, and 1,000 tasks with multi-tool diagnostics, which is the relevant point here: tool-using agents fail at discovery, invocation, sequencing, and recovery, not only final-answer wording.