
Same Model, Different Product: The Case for Harness Engineering
Harness engineering, the code wrapped around an AI model, now drives more of the performance gap than the model you pick.


You can run the same model inside two coding agents and get two different products.
Put Claude Sonnet under Claude Code and under Cursor. Same weights, same context window, same benchmark scores on paper. In practice you get different token burn, different success rates, different cost per task, a different feeling about whether you can leave the thing running. Adam Elkassas, who builds with both, put it plainly.
Same Sonnet underneath Claude Code, Cursor, Cline, and a dozen no-name CLIs, and they feel like completely different products. 1
The size of that gap is now on the record. On the same model and the same benchmark, swapping the harness can move the score by as much as 6x, a figure documented across agent research and restated in a March 2026 Stanford and MIT paper on harness design. 2 Not the weights. Not the prompt. Not fine-tuning. The wrapper.
LangChain showed it from the other direction. Their coding agent, deepagents-cli, climbed from 52.8% to 66.5% on Terminal Bench 2.0, from outside the Top 30 into the Top 5, while the model underneath, GPT-5.2-Codex, stayed fixed. 3 The score moved nearly 14 points. The model did not move at all.
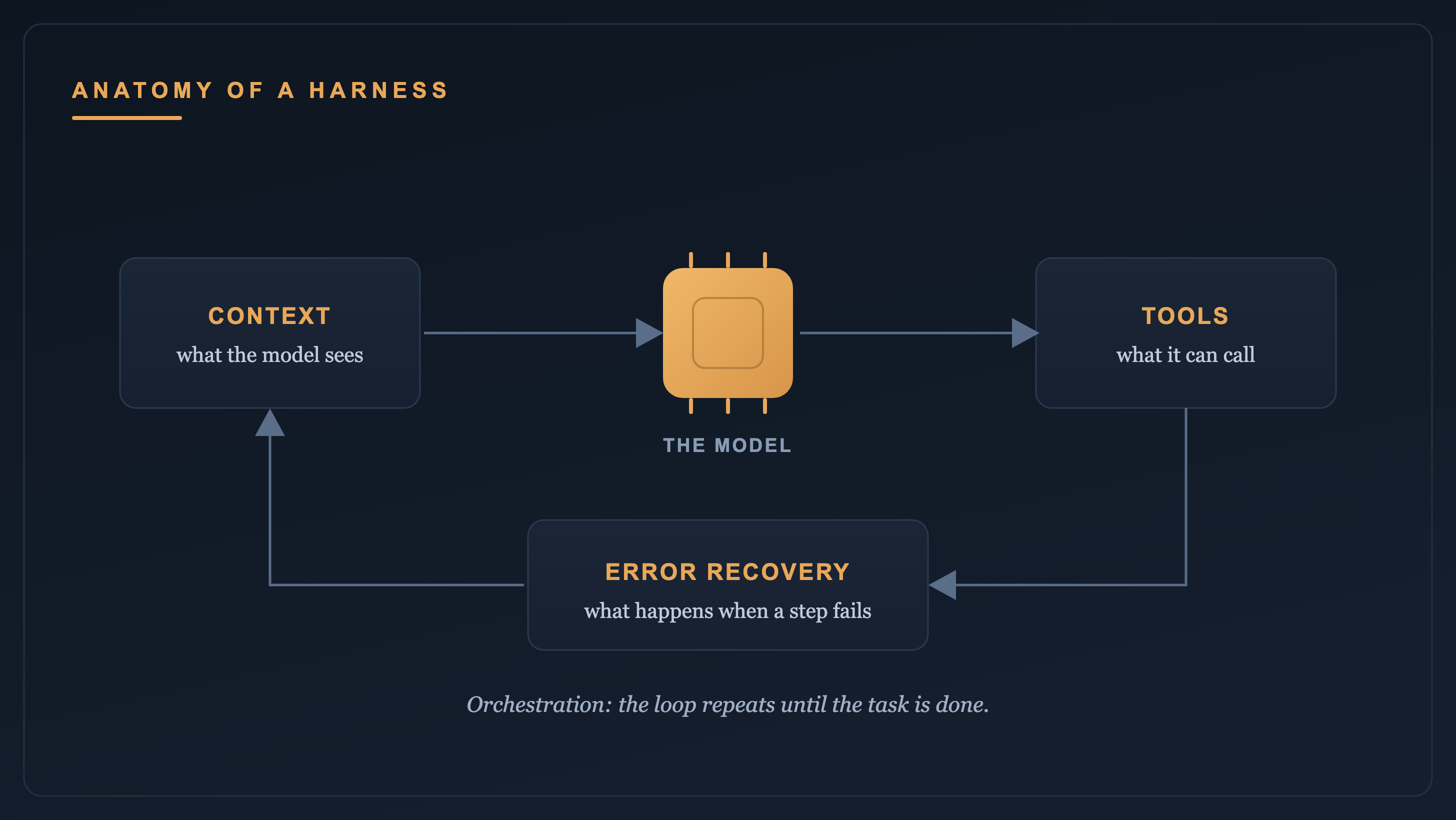
The variable that moved the score has a name. The harness: the code that decides what the model sees, when it runs again, which tools it can reach, and what happens when it fails. Changing it well has become its own discipline now, with its own name: harness engineering. Most teams spend their attention choosing the model. The performance they are chasing lives one layer out, in code most of them have never opened.
For beginners: what is a harness? The model generates text. The harness is everything around it that turns a raw text predictor into something that can do work: the loop that calls the model again and again, the memory of what happened earlier, the list of tools it is allowed to use, the rules for what to do when a step breaks. Two products can run the identical model and still behave differently, because the harness around each one makes different choices. When people say “Claude Code feels different from Cursor,” the harness is most of what they are feeling.
Where harnesses diverge
Four decisions separate a harness that gets 66% from one that gets 52%. None of them touch the model.
What it keeps
Every harness has to decide what to keep as the conversation grows and what to throw away. A long task fills the context window with resolved debug cycles, completed file edits, and conversational noise. Keep all of it and the model drowns in its own words. Throw away the wrong thing and it forgets why it started.
The simple approach keeps the last N messages and discards the rest. That means a stale file read from twenty minutes ago competes for the model’s attention with the task in front of it. Claude Code’s pruning logic does something different: it keeps the plan and trims the chatter, holding on to the original intent and the current task state while dropping the resolved sub-tasks. What a harness keeps in context turns out to be one of the biggest levers it has.
If you are running an agent on recency alone, you are leaving performance on the table and paying for the privilege in tokens.
What it does when it fails
When a step breaks, a weak harness has one response: retry. A strong one knows why it broke and answers each failure differently. Claude Code’s loop carries seven explicit reasons it might be running again. It hit the output-token ceiling, so it retries at a higher limit. The prompt overflowed, so it compacts and continues. A tool returned, so it injects the result. The reason is stored and handed back to the model on the next turn.
That is the difference between an agent that silently restarts and one that knows it hit a token limit, compacted the context, and is carrying on. Collapse every failure into a single “retry” and you throw away the signal that tells the model what to do next.
A harness that treats a token overflow and a broken tool call as the same event has discarded the one piece of information that would have let the model recover.
What it lets the model touch
Show a model fifty tools on every turn and it makes worse decisions about which to use. Manus cut their agent down to roughly 20 atomic function calls after watching performance fall whenever the model met an unfamiliar tool. Claude Code reveals tools as they become relevant: the file-read tool while exploring, the commit tool only once there are changes to commit.
The format of a single tool can move the number more than a model upgrade. Can Bölük’s hashline edit format, where the model points at lines by a content hash instead of reproducing the exact text, took one model’s edit success from 6.7% to 68.3% and cut another model’s output tokens by 61%. 4 He changed one tool and improved fifteen models. None of the models changed.
How the loop is built
The execution loop itself is an engineering decision. Claude Code runs a single state machine, roughly 1,400 lines, one instance per conversation, holding a mutable record of message history, token usage, and permissions. Early versions used recursion and switched away once the call stack grew without bound on long sessions.
This is the layer where LangChain found its 13 points. The gains came from structured verification loops that scored intermediate steps, loop-detection that caught the model spiralling on the same hallucination, and tracing at scale that showed which transitions were failing silently. A team that can see which step corrupted the run can fix it. A team that only sees the final output cannot.
Why the labs leave it on the table
If harness design moves the number this much, the obvious question is why the people who make the best models do not also ship the best harness. The answer is in their incentives.
A good harness uses the fewest tokens it can to finish the task. When an independent builder finds token waste, they ship the fix that night, because every token they cut is money back in their user’s pocket and a reason to stay. When a frontier lab finds the same waste, it becomes a low-priority ticket that loses every sprint to a feature that drives more API calls.
A good harness uses the fewest tokens possible. When an independent harness-maker finds token waste, they ship the fix that night. When a frontier lab finds it, it is a P2 that loses every sprint.
This is structure, not malice. Anthropic has committed around $50 billion to data centres. OpenAI’s Stargate is past $400 billion. Every one of those GPUs needs tokens flowing through it to earn its keep. A harness that cut token use by 5x would save users money and shrink the revenue the buildout was financed against. The independent builder wakes up trying to cut tokens. The lab wakes up trying to fill a gigawatt of compute. Those are opposite jobs, and they produce opposite harnesses.
Why the advantage lasts
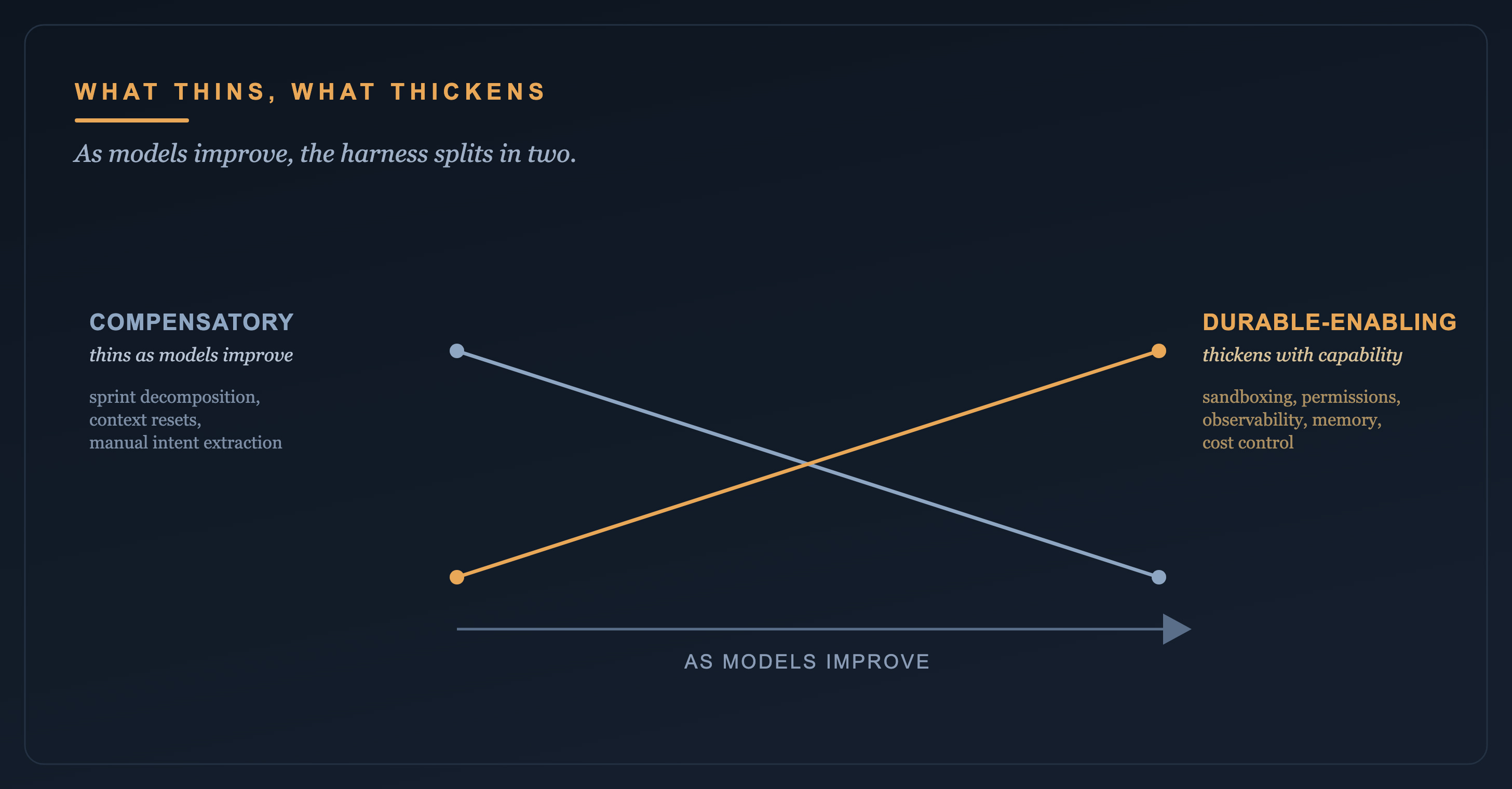
It would be easy to read all this as a 2026 quirk that the next model erases. Some of it is. The parts of a harness that exist to patch a model’s current weakness do shrink as models improve. Anthropic removed an entire planning step with one model release, because the model no longer needed the work broken down for it.
The parts that do what a model structurally cannot do are moving the other way. Sandboxing, permissions, observability, memory: a more capable agent needs more of each, not less. The harness is not shrinking as a whole. The shrinking parts and the thickening parts are different parts.
The market has noticed. Surveys put Claude Code at as much as 54% of the coding-agent market, on a reported $2.5 billion annualised run-rate; the wrapper is now a product people pay for directly. 5 In May 2026 DeepSeek, a model-first lab if there ever was one, posted to hire a Harness Team, with the internal line “Model + Harness = Agent.” When even the labs that sell models start staffing the layer above the model, that tells you where the value is settling.
A model-first lab hiring a harness team is the clearest signal yet. The value is settling in the layer above the model.
For an investor the read is structural. A specific harness optimisation is temporary, and the next model may erase it. What compounds is the discipline of building harnesses, and the tooling and memory a team carries from one model generation to the next. That is the part a team owns. The model underneath it is rented.
The position has a clean exit. If a frontier lab ships a first-party agent that beats every third-party harness on the same model by more than 10% on Terminal Bench, the independent-harness edge is gone. If the open-source ecosystem converges on one dominant design and the 6x gap collapses below 2x, this was a transitional observation, not a structural one. Watch those two numbers. They are where the thesis dies if it is going to.
The Durability Curve tracks where value is moving in AI and markets, before the consensus reprices it. A new structural breakdown most weeks.
Audit your own harness
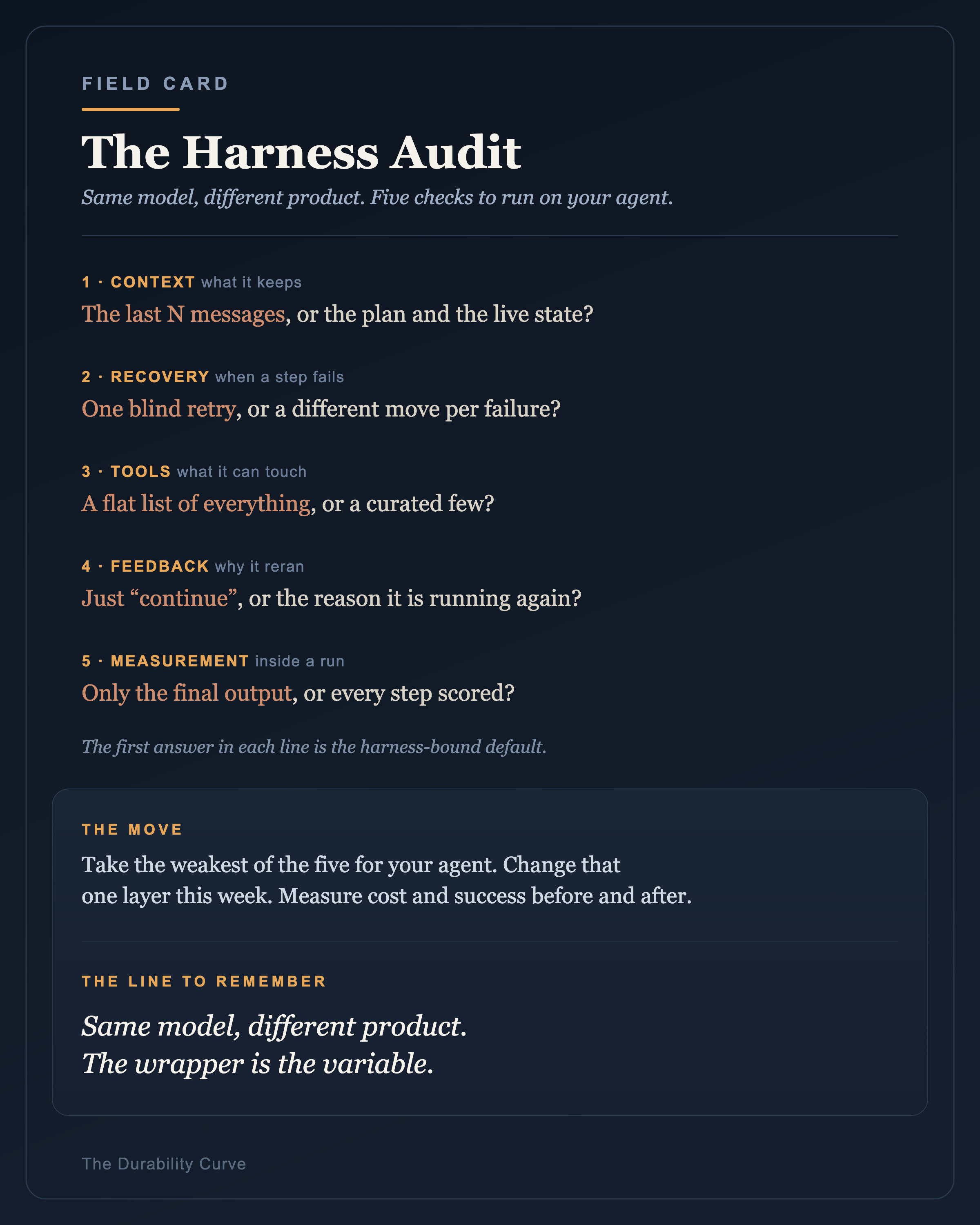
You do not need the source code of Claude Code to find out whether your agent is harness-bound. Five questions locate the gap, and a team shipping an internal agent can answer all five about their own setup in an afternoon.
Start with what it keeps. Does your harness hold the plan and the current state, or the last N messages? If it is recency, the cheapest gain you have is sitting in the pruning logic, and you have probably never touched it.
Then what it does when it fails. Does a token overflow, a tool error, and a timeout produce three different responses, or one “retry”? If it is one, the model is recovering blind.
Then what it can touch. Does the model meet a curated set of tools, or a flat list of everything? If the list is long, trim it before you change anything else.
Then whether it knows why it is running again. When your loop calls the model back, does it pass the reason, or just “continue”? An agent told only to continue makes its next decision with no idea what just happened.
Then whether you can see inside a run. Can you score the intermediate steps, or only the final output? If step two fails quietly, step five inherits the corruption and you will blame the model for it.
A team that answers these honestly usually finds the same thing: they have changed the model three times and never opened the harness once.
The one-week test
Pick one agent you are running. Do not change the model this week. Instead, find the harness layer you have never touched, almost always context pruning or error recovery, and change that one thing. Measure cost per task and success rate before and after.
Most teams have never opened the part of their stack that decides what the model sees and what happens when it breaks. That is usually where the cheapest improvement is hiding, and you do not have to switch models to find it.
The model you picked is the part everyone can see. The harness is the part doing the work.
When you last reached for a better model, was the bottleneck ever the model?
Adam Elkassas, pre.dev, "Frontier labs won't build good harnesses. Their incentives won't let them." Supporting capex context: Anthropic's $50 billion US data-centre commitment with Fluidstack (announced November 2025) and OpenAI's Stargate, past $400 billion in planned investment toward a $500 billion, 10-gigawatt target. https://pre.dev/blog/frontier-labs-wont-build-good-harnesses-their-incentives-wont-let-them/
Yoonho Lee, Roshen Nair, Qizheng Zhang, Kangwook Lee, Omar Khattab, and Chelsea Finn, “Meta-Harness: End-to-End Optimization of Model Harnesses,” Stanford IRIS Lab, MIT, and KRAFTON, arXiv:2603.28052, 30 March 2026. The paper opens by noting that changing the harness around a fixed model can produce a 6x performance gap on the same benchmark, citing prior agent research. Its own framework lifts a fixed model from 27.5% to 37.6% on TerminalBench-2, and from 58.0% to 76.4% on a stronger model, by searching for better harnesses. https://arxiv.org/abs/2603.28052
LangChain, “Improving Deep Agents with harness engineering”: deepagents-cli rose from 52.8% to 66.5% on Terminal Bench 2.0, from outside the Top 30 into the Top 5, on a fixed GPT-5.2-Codex, by changing only system prompts, tools, and middleware hooks. https://www.langchain.com/blog/improving-deep-agents-with-harness-engineering
Can Bölük, “I Improved 15 LLMs at Coding in One Afternoon. Only the Harness Changed.,” 12 February 2026. The hashline edit format (the model references lines by a content hash rather than reproducing exact text) took Grok Code Fast 1 from 6.7% to 68.3% and cut Grok 4 Fast’s output tokens by 61%, with gains across the model set. https://blog.can.ac/2026/02/12/the-harness-problem/
Surveys put Claude Code’s share of the coding-agent market at 42–54% (Menlo Ventures State of Generative AI, cited via MindStudio), on a reported ~$2.5 billion annualised run-rate (reported figures; Anthropic is private). In May 2026 DeepSeek established a Harness team, part of a wider shift in AI coding tools from “model battles” to “engineering battles.” https://www.mindstudio.ai/blog/claude-code-2-5-billion-annualized-revenue-terminal-tool and https://finance.biggo.com/news/rsqbS54BDXrLZJaA6kwD