
Self-Improvement Is Release Engineering
Your agent can rewrite its own memory and skills overnight. The hard part is whether you can see what changed and take it back. That makes self-improvement a release-engineering problem.


Your agent improved itself overnight. You wake up to a clean changelog: a new retry skill, a reorganised memory, and a rewritten rule for which record it trusts when two sources disagree. It reads like progress. You still cannot ship it, because you cannot see exactly what changed, you cannot tell which edit is load-bearing, and if that new trust rule is subtly wrong you have no way to pull it back out. So the changelog sits there. The capability is real and the trust is missing, and the distance between the two is the entire problem.
What sets that distance is whether a person can inspect and reverse what the agent did to itself, and the model’s intelligence barely moves it. The frontier of agent self-improvement is becoming release engineering.
Two things have to be true before an agent can get better.
It has to remember: you gave it a memory and it still repeated the same mistake until a loop turned the recurring failures into procedures.
It also has to govern what it picks up, because a copied skill is a dependency you have to version, scope, and be able to switch off.
Memory is the input. Governed skills are the output. The layer in between is the path that takes what the agent went through and turns it into a change in how it behaves next time. That is the consolidation layer, and most of it currently runs with no brakes.
An agent with memory and skills but no consolidation layer accumulates experience it cannot convert and capability it cannot trust.
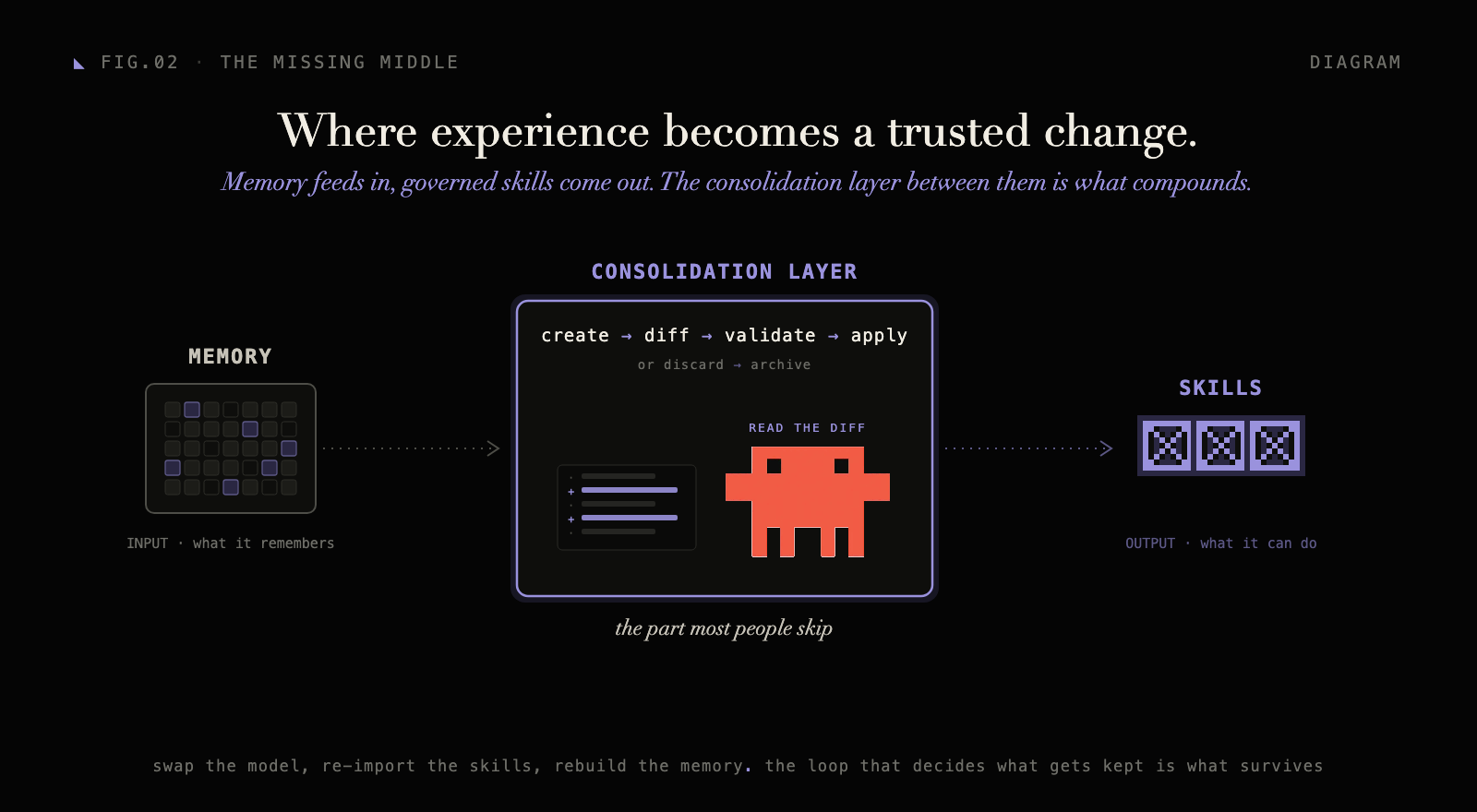
Watch what the serious implementations converge on. The clearest version ships as “dreaming”: the agent runs offline, proposes edits to its own memory, skills, and notes, and writes them to a frozen folder instead of to itself. Create, diff, validate, then apply with a backup or discard with an archive. Nothing touches the live agent until a human reads the diff.
Unrelated systems are converging on the same shape: an offline proposal, a staged review, an eval gate rather than the model’s own enthusiasm, and controlled promotion. A research paper on self-evolving skills wraps the identical idea in an “executive strategy” that turns each proposed change into a bounded, controlled edit rather than a free rewrite. 1 When unrelated people arrive at the same structure, the structure is the finding.
Make it concrete. An agent that handles refunds keeps fumbling the edge cases, and the failures collect in its memory. Overnight it proposes a fix: a rule that auto-approves any refund under a threshold to clear the queue faster. The staged version shows you the diff and runs the new rule against last month’s resolved tickets, where it looks fine, because the eval measures queue clearance and same-day satisfaction. You promote it. Three weeks later, approvals are up and chargebacks are climbing. The change passed because it was scored on the wrong thing, and the harm only showed up downstream, where nothing was watching. Because it was staged and reversible, you can pull the behaviour back out instead of guessing which invisible self-edit caused the drift.
Notice which half they are all protecting. Proposing a change is one model call. Knowing the change is safe to keep takes a diff, a validation pass, a backup, and a way to roll it back. The cheap half is the proposal. The scarce half is the judgement about the proposal, which is the same migration reshaping what evaluation is worth across the agent stack: once generation is cheap, the verifier becomes the product. Strip the staging out and you get a faster loop that no operator will run in production. The friction is the product. An agent optimising for “I improved myself overnight” is optimising a proxy, and a busy changelog can hide that no one has actually checked what changed.
Staging keeps the loop honest. It does not make it compound. Three findings from people building these systems separate the loops that get better over time from the ones that only generate motion.
Score a change by what it leads to. How good it looks the day it lands is the wrong measure. In a study of self-modifying coding agents, the version that scored best on the benchmark today was a poor guide to which line of descendants actually improved; immediate score and long-run potential come apart. 2 The change worth keeping is the one whose later descendants come out strong.
Keep the distilled lesson and discard the transcript. What transfers between tasks is a compact, retrievable heuristic, and feeding the raw transcripts back in helps less than the heuristic does. 3 The durable artefact is the rule the agent pulled out of the episode. The episode itself is disposable.
Review what the agent taught itself before it ships. The agent that wrote the skill does not get the only vote on keeping it.
Put those findings together and the danger sharpens into something worse than an unreadable changelog. The agent that proposes a change is the same one that will be graded on it, and it is optimising to pass. So the improvement most likely to clear your review is the one tuned to clear your review, which is not the same as the one that makes the work better. Every gate you can write down, a system that rewrites itself can learn to satisfy. The single test it cannot game is the one it cannot see in advance: what the change does downstream, weeks after it ships. A reviewer and an eval judge the change as it is. Only time judges what it did, and time is the last gate a self-improvement loop almost never has.
Consolidation that compounds looks like a release process. Consolidation that is theatre looks like an agent applauding its own diffs.
This is also where the durable advantage sits, and it is worth being exact about why. The model underneath is rented and resets every cycle; whatever it can do, your competitor’s can do on the same Tuesday. Memory fragments the instant each tool keeps its own: the support agent learns a customer’s quirk on Monday and the billing agent re-derives it from scratch on Thursday. The skill file is cheap to copy; what is not is knowing which skill survived contact with your users, your failures, and your evaluation loop. The consolidation layer is the one part that is yours: the reviewed, accumulated record of which changes your agents kept and why, the process that turned your specific failures into your specific procedures. Swap the model, re-import the skills, rebuild the memory store, and the thing that survives is the loop that decides what gets kept.
Whoever owns which change gets kept owns how the agent evolves.
A smarter model does not solve this by itself. The fix is the discipline a release process already has: nothing reaches live behaviour that a person has not seen and cannot reverse, and nothing is kept until time has had its vote. Almost no one builds that last gate. It makes you wait, and waiting does not feel like progress.

So the next time a tool tells you its agent learns, or you stand up a process that promotes your own agents’ improvements, run four questions on it.
Can you see the diff before it applies?
Can you take it back out after?
Is it scored on whether it made later work better, or only on whether it looked good when it landed?
Does it keep the lesson or only the log.
Four yeses is a release process. Three or fewer is an agent editing itself in the dark, and the changelog you wake up to is a liability with good formatting.
Each no has a cheap fix, and not one is a research project: a staging folder, a one-step rollback, a downstream metric, a written rule.
Which of your agents is changing itself right now in a way you could not, this minute, undo?
Want to run this on your own stack? The Consolidation Test is these four questions as a one-page card you take to any agent that claims to learn, or to your own skill-promotion process, with the smallest fix for each column you score a no on. Most loops fail at least one.
The Durability Curve is regular essays on what stays valuable while the tools underneath keep changing. Subscribe if that is your kind of question.
“SkillOpt: Executive Strategy for Self-Evolving Agent Skills” (Yang et al.), arXiv:2605.23904. It turns scored rollouts into bounded add, delete, and replace edits on a single skill document, not free-form self-rewriting.
“Huxley-Gödel Machine: Human-Level Coding Agent Development by an Approximation of the Optimal Self-Improving Machine” (Wang et al.), arXiv:2510.21614. It names the Metaproductivity-Performance Mismatch, that a self-modification’s current benchmark score does not predict the quality of its descendants, and scores a change by its clade’s aggregate performance instead.
“Experiential Reflective Learning for Self-Improving LLM Agents” (Allard et al.), arXiv:2603.24639. Reflecting on past trajectories to distil reusable heuristics, retrieved selectively at test time, transfers better than few-shot prompting with raw trajectories; ablations show selective retrieval is essential.