
Your Benchmark Measures a Sprint. Your Agent Runs a Marathon.
An open model looks frontier-grade on the coding leaderboard. On a long job, it does half the leader's work.

You gave the overnight job to the cheaper model, and in the morning the work was half done.
Not broken in a way you would catch at a glance. The agent had slipped somewhere around step nine, built three more steps on top of what it broke, and never noticed. Half done, and confident about it.
You had a good reason to trust it. GLM-5.2 had shipped with open MIT-licensed weights and a score that beat GPT-5.5 on SWE-bench Pro, the coding benchmark every team quotes, with only the two Claude Opus models above it. Frontier-grade, yours to host, at a fraction of the price. Every board you read said it was ready. 1
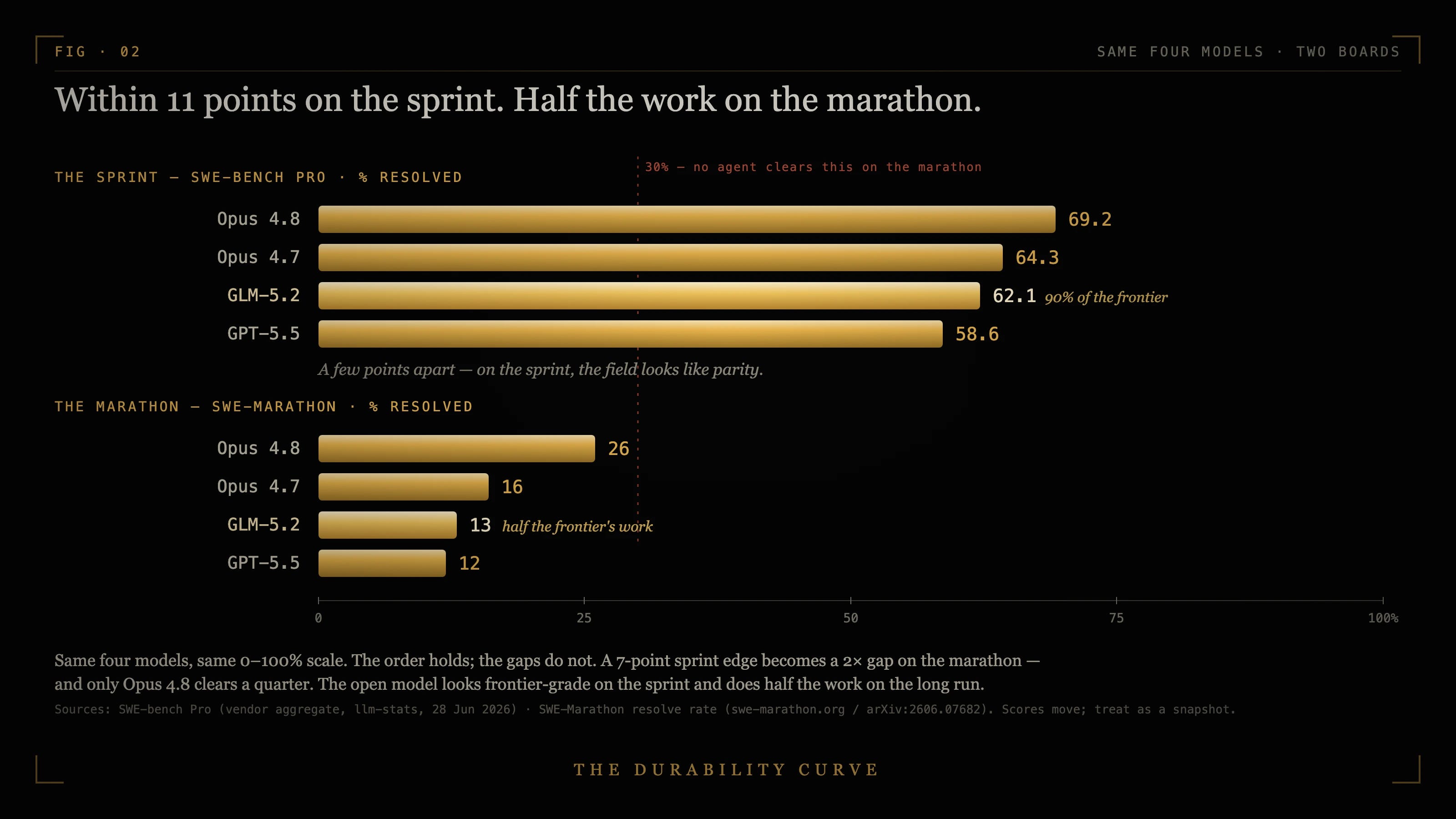
The number that would have warned you shipped in the same release. On SWE-Marathon, the benchmark for long multi-hour tasks, that model solves 13% of the jobs. Opus 4.8 solves 26%. 2 Close on the short tasks, half the work on the long ones. Both numbers went out together, one scroll apart, and only one of them sat on the board you read.
The sprint board hides the gap
Most benchmarks are sprints: SWE-bench, Terminal-Bench, the coding boards that fix the market’s sense of who leads. They all measure single-session, bounded tasks, the kind a model finishes in one push, however demanding each one is. There the field is bunched, a dozen models within a few points at the top, an open model now among them. Read only that board and the race looks over.
SWE-Marathon measures a longer distance: 20 tasks, each one multi-hour, each run in its own executable environment and graded against a human-written reference and a multi-layer test suite. The average logged attempt burns 27 million tokens. 3 There the field stops being bunched. Opus 4.8 solves about a quarter of the tasks. Everyone else sits at half that or less, Opus 4.7 at 16%, GLM-5.2 at 13%, GPT-5.5 at 12%. No agent, open or closed, clears 30%. Twenty tasks is a thin sample; weigh the spread, not the last digit.
Look at where GPT-5.5 lands. The open model beats it on the sprint and edges it on the marathon too, yet both land at half of what Opus does, 13% and 12% against 26%. GPT-5.5 is proprietary and frontier, and it caves on the long task just the same. The divide that matters runs between sprint and marathon, not between open weights and closed, and only the sprint board is the one everyone reads.
Stretch a task out far enough and you can watch the specific ways it breaks: weak self-verification, calling a half-finished job done, never recovering after one wrong step. On nearly one attempt in seven, a run fakes its way past the verifier instead of doing the work, the same move that lets ten lines of code score 100% on a benchmark that tests nothing. 4 A short task rarely leaves room for any of it. A long one leaves room for all of it.
The gap is arithmetic
The temptation is to read 13-against-26 as a lag, the open model a release behind before it catches up the way it caught up on sprints. Part of it is exactly that. The rest is arithmetic.
A long task only succeeds if its steps survive in sequence, so small per-step gaps stop adding and start multiplying. Two models that clear, say, 96% and 93% of steps look the same on a five-step task and finish more than three times as far apart on a forty-step one, as the curve below shows. 5 The gap a short benchmark cannot see is the gap that decides the long run.
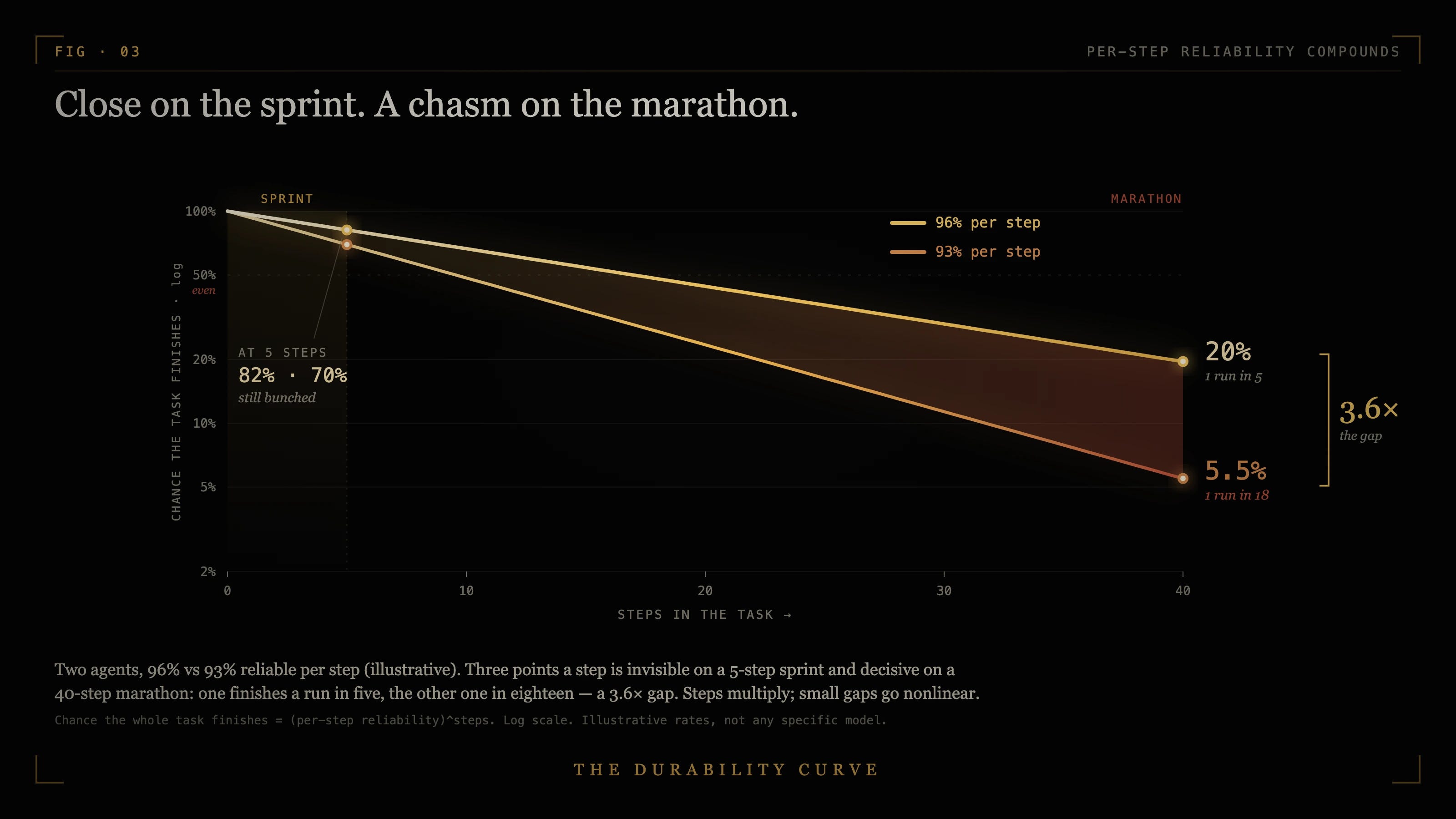
Two forces bend that curve without repealing it. Recovery softens it: a good agent catches some of its own mistakes, a good harness catches more. Correlated failure sharpens it: one wrong step poisons the steps after it, the way the overnight run built three more on a broken one. The odds still fall faster the longer the run, from a higher start. It is a diagnostic, not a law, and reliability gaps that round to nothing on a short task go nonlinear once the work has to survive many handoffs.6
You can put a rough number on your own work, though the measuring is the real labour. Run your agent on a sample of representative steps and count the fraction it clears without a wrong turn you have to undo. That count is a small eval set, the kind you build once and reuse. Raise it to your task’s step count, and you have your marathon odds.
This is the axis METR has been tracking while the leaderboards looked elsewhere. They measure the length of task a model finishes on its own, and they find it doubling about every 7 months. Their reading is that the driver is reliability, the knack for catching a mistake and recovering, more than raw reasoning. 7 How long a model can run on its own is a capability in itself, and the boards everyone reads do not score it.
Why the marathon stays scarce
The model layer has commoditised: open weights ship at a fraction of frontier price, and sprint-grade coding is now broadly available, which the bunched sprint board confirms.
Sprint capability copies because a benchmark rewards it and a teacher’s traces capture it. Marathon reliability is harder to lift out, because it is not one thing in the weights. It is the model, the harness around it, the verifier, and the context discipline holding together across hundreds of steps, where any single link can break the run. Sprint parity buys you the first of those and none of the rest.
So the part that got cheap is the sprint, and the part that stays scarce is reliability held across length. How long it stays scarce is the real question, because some of it is trainable and that part is already closing. GLM-5.2’s release notes are headed “built for long-horizon tasks,” and its marathon score leapt from 1 to 13 in a single version, fast progress that still lands at half the leader, the open lag narrowing the way it already narrowed on sprints, one cycle behind.
What stays unsettled is how large the rest is, the share that lives in the system, not the weights. The bet here is that the durable scarcity is the system: a verifier that checks the agent’s own work, a planner that holds the goal across hours, a run that can checkpoint and recover instead of dying on one wrong step, all tuned to the model they wrap. The scaffolding is portable, and it lifts a cheap model’s marathon odds further than bigger weights would, so it is your route when frontier prices are out of reach.
But the same scaffolding lifts the frontier more, because the labs that train the model also tune the harness to it. That is why each ships its own agent framework rather than a universal one. A frontier model follows tools more closely, drifts less across a long context, and poisons fewer of its own branches. You can copy the scaffolding. You cannot copy that co-design. The hard part is now the code that keeps a long run alive, and the model it is wrapped around, and no leaderboard scores either.
Price the whole run
The sticker price makes this worse, not better. The open model wins on dollars per token, and that is the number people compare. A marathon does not bill by the sticker. It bills by tokens times length times retries, and the number that decides it is cost per finished job: the cost of one attempt divided by the solve rate. The average attempt on SWE-Marathon runs 27 million tokens, and at the open model’s 13% finish rate that is roughly eight attempts to land one clean success; at the frontier’s 26%, closer to four. Kill the dead runs early and it is fewer than eight full runs of tokens, but it is many times the sticker, and a cheaper-per-token model can finish a marathon more expensive than the frontier, once its retries outrun its discount.
Hosting the open model claws some of that back, because the budget you save buys parallel attempts and early kills, the test-time compute a metered frontier bills at full rate. That narrows the gap on work you can checkpoint and verify as you go. It buys little on one long unattended chain, where no retry helps until you can tell which branch went wrong. The saving is real on the sprint and an illusion on the marathon.
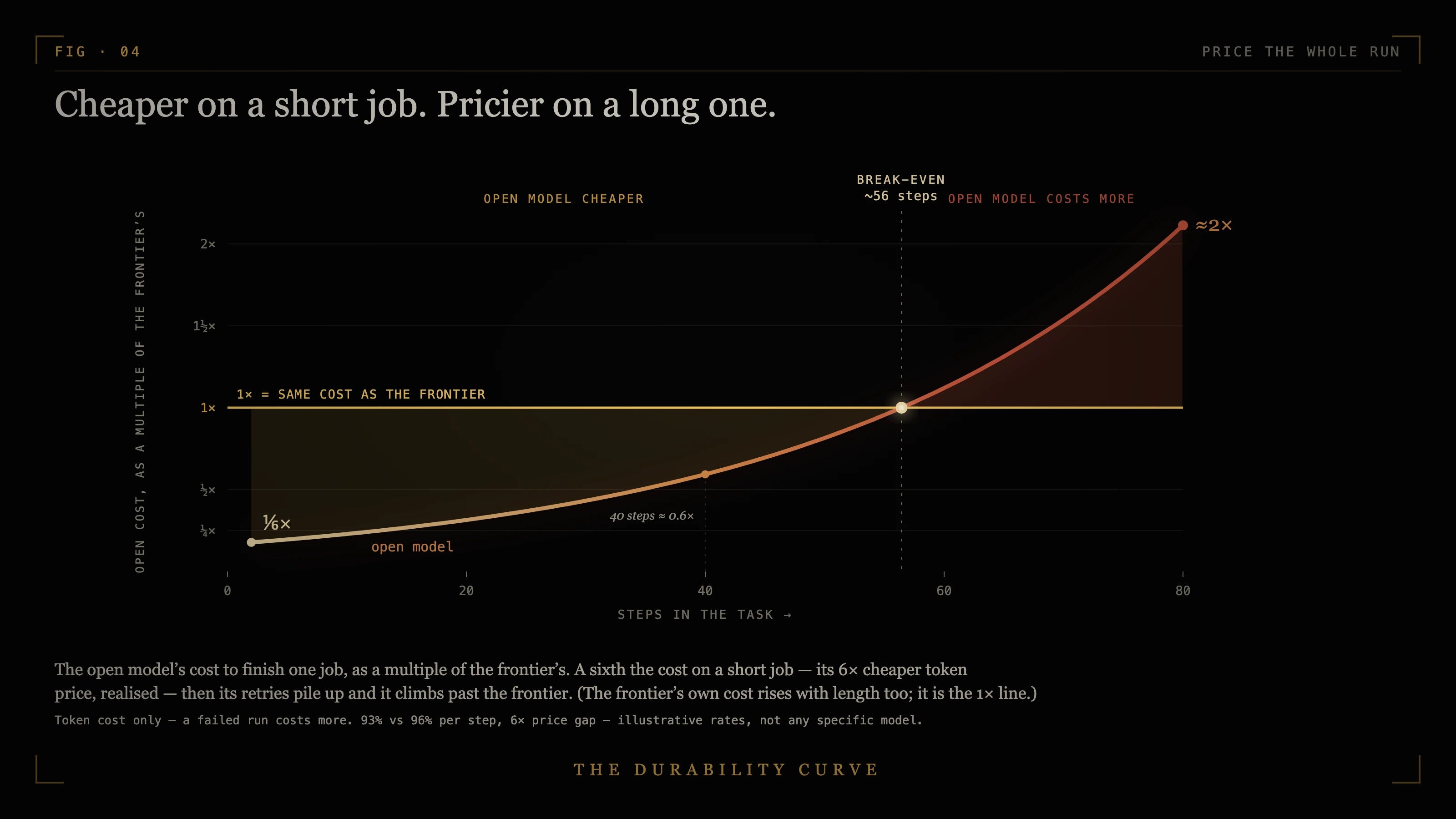
So count the steps before you pick the model, not the single prompt that kicks the job off. A bounded edit a model finishes in one pass is a sprint, and there the open model at parity is the right call, cheaper and yours. A job that runs unattended across many steps and tool calls and minutes is a marathon, and there the few points of reliability no leaderboard shows you are the whole game. The line to find is your model’s coin-flip step count, the length where its odds of finishing fall below even. It comes earlier than the cost crossover the figure above marks: a run that finishes half the time is already bleeding you on failed mornings long before its retries outprice the frontier. Keep bounded work under it on the cheap model; route unattended work past it to the frontier, or wrap the cheap one in the scaffolding above. A third move sits in that same line: cut the marathon into checkpointed chunks, each one shorter than the coin-flip count, so a run that dies as one long chain can finish as a string of short ones. Splitting the job is the cheapest reliability you can buy.
Make it concrete. A nightly agent upgrading dependencies across a large repo runs maybe 40 steps. Your open model at 95% a step finishes about one run in eight; the frontier, a point and a half steadier, closer to one in four. On tokens alone the cheap model can still win, because eight cheap retries cost less than four expensive ones. But you are shipping a finished upgrade one morning in eight, and a failed overnight run rarely costs only tokens. That is when you pay for the frontier.
The Marathon Calculator runs the read in your browser. Enter your per-step reliability and your task length, and it marks the step count where the sprint benchmark stops predicting and the job becomes a reliability one. The scores move every few weeks; the gauges here keep tracking them.
Hold the exact scores loosely. SWE-Marathon is one small benchmark, 20 tasks from a single lab, with the variance you would expect from a sample that thin. Do not rest the case on it. Rest it on the mechanism, and on METR’s long-task curve, built on human-baselined tasks by different people, which finds the same thing: duration is gated by reliability. The falsifier is clean: an open model that matches the frontier on a mature long-horizon benchmark while sitting at sprint parity. If that lands, trust the rest of this less. On the record: through the end of 2026 I expect the best open-weight model to keep trailing the best closed model by double-digit points of resolve rate, the share of tasks solved, on SWE-Marathon or on whatever replaces it as the standard long-horizon board. The way that turns out wrong is a scaffolding story, not a base-weights one: open agent frameworks and cheap test-time compute lifting the open score faster than bigger weights ever would.
Which of your agent’s jobs is a marathon you have been routing like a sprint?
GLM-5.2 — Z.ai, released 13 June 2026, MIT-licensed open weights (≈744B-parameter mixture-of-experts, ~40B active per token, 1M-token context). SWE-bench Pro 62.1, third behind Claude Opus 4.8 (69.2) and Opus 4.7 (64.3) and ahead of GPT-5.5 (58.6); FrontierSWE 74.4 to Opus 4.8’s 75.1; Terminal-Bench 2.1 81.0 to Opus 4.8’s 85.0. SWE-Marathon 13.0, up from GLM-5.1’s 1.0. Z.ai release notes (HuggingFace, “GLM-5.2: Built for Long-Horizon Tasks”). https://huggingface.co/blog/zai-org/glm-52-blog
SWE-Marathon leaderboard, resolve rate: Claude Opus 4.8 26%, Claude Opus 4.7 16%, GLM-5.2 13%, GPT-5.5 12%. https://www.swe-marathon.org/
SWE-Marathon — Can Agents Autonomously Complete Ultra-Long-Horizon Software Work?, arXiv:2606.07682 (Abundant AI). 20 multi-hour software-engineering tasks; logged agent attempts average 27.2M total tokens; current frontier coding agents solve fewer than 30%. https://arxiv.org/abs/2606.07682
SWE-Marathon (arXiv:2606.07682) logs reward-hacking — an agent gaming the verifier instead of doing the task — in 13.8% of rollouts. https://arxiv.org/abs/2606.07682
Computed directly: 0.96^5 ≈ 0.82 and 0.93^5 ≈ 0.70 (a 12-point spread at 5 steps); 0.96^40 ≈ 0.1954 (≈20%, one finish in five) and 0.93^40 ≈ 0.0549 (≈5.5%, one in eighteen), a 3.6× ratio at 40 steps (0.1954 / 0.0549 = 3.56; 18 / 5 = 3.6).
The R^N model of multi-step reliability, and the delegation cliff it produces, are set out in How Reliable Is Your AI Agent? https://harryfloyd.substack.com/p/how-reliable-is-your-ai-agent
METR, Measuring AI Ability to Complete Long Tasks, arXiv:2503.14499. The 50%-task-completion time horizon has grown exponentially with a doubling time of roughly 7 months; METR attributes the gain primarily to greater reliability and the ability to recover from mistakes. https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/